



Özet
Lif bitkileri yetiştiriciliği, tarihsel süreç içinde emek yoğun ve deneyime dayalı bir üretim pratiği olarak şekillenmiştir. Ancak günümüzde hızla gelişen dijital teknolojiler, bu geleneksel üretim anlayışını köklü biçimde dönüştürmektedir. Yapay zekâ, makine öğrenmesi, derin öğrenme, Nesnelerin İnterneti (IoT) ve biyoteknoloji gibi alanlardaki ilerlemeler; pamuk, keten ve kenevir gibi stratejik lif bitkilerinin üretiminde verim artışı, kalite kontrolü ve sürdürülebilirlik açısından somut katkılar sunmaktadır.
- Giriş
Endüstri bitkileri, hasat edildikten sonra doğrudan kullanılmayıp çeşitli işleme süreçlerinden geçirilen ve ham madde olarak sanayi üretimine katkı sağlayan tarımsal ürünleri kapsamaktadır. Bu bitkiler lif, nişasta ve şeker ile yağ bitkileri olmak üzere üç ana grupta değerlendirilmektedir. Lif bitkileri grubunda başta pamuk, keten ve kenevir olmak üzere jüt, rami, sisal gibi türler yer almakta; bu bitkilerden tohum, sap, yaprak ve meyve gibi farklı bitki organlarından lif elde edilmektedir.
Dünya genelinde pamuk, tekstil sanayisinin vazgeçilmez ham maddesi konumundadır. Tarım ve Orman Bakanlığı verilerine göre Türkiye, pamuk üretiminde önemli bir konuma sahip olup Çukurova, Ege ve Güneydoğu Anadolu Bölgeleri başlıca üretim merkezleridir (Tarım ve Orman Bakanlığı, 2022). Keten ve kenevir ise hem tekstil hem de farmasötik, inşaat ve biyoyakıt sektörleri için stratejik öneme sahip bitkilerdir.
Geleneksel yetiştiricilik yöntemlerinde insan gözlemine ve deneyimine dayalı kararlar; ekim zamanı, sulama planlaması, hastalık tespiti ve hasat zamanının belirlenmesi gibi kritik süreçlerde belirleyici rol oynamaktadır. Ne var ki bu yaklaşım, değişken iklim koşulları, artan nüfusun yarattığı gıda ve lif talebi ve azalan tarımsal işgücü göz önüne alındığında yetersiz kalmaktadır. Bu bağlamda Dijital Tarım veya Tarım 4.0 olarak adlandırılan yeni paradigma, tarımsal üretimde veri odaklı karar almayı merkeze koymaktadır (Wolfert ve ark., 2017). - Lif Bitkilerinin Agronomik Özellikleri ve Üretim Süreçleri
2.1 Bitki Tanımlama ve Sınıflandırma
Lif bitkilerinin doğru tanımlanması, üretim planlamasının temelini oluşturmaktadır. Pamuk (Gossypium hirsutum L.) kazık köklü bir yapıya sahip olup koza olarak adlandırılan meyvesinden lif elde edilmektedir. Keten (Linum usitatissimum L.) sapından lif ve tohumundan yağ üretilen çift amaçlı bir bitkidir. Kenevir (Cannabis sativa L.) ise uzun, sağlam saplarından elde edilen lifleriyle hem tekstil hem de teknik alanlarda kullanılmaktadır. Bu bitkilerin kök sistemi, gövde uzunluğu, yaprak biçimi, çiçek yapısı ve tohum özellikleri; geleneksel sınıflandırma yöntemlerinde temel kriterleri oluşturmaktadır. Ancak morfolojik benzerlikler, özellikle erken gelişim dönemlerinde, türlerin ayrıştırılmasını zorlaştırabilmektedir.
2.2 Toprak ve İklim İstekleri
Lif bitkileri güneşli ve sıcak iklimleri tercih etmekte, killi-tınlı ve kumlu-killi topraklarda en iyi verimi vermektedir. Pamuk, toprak sıcaklığının 13-15°C'yi bulduğu nisan-mayıs döneminde ekilmektedir. Keten ülkemizde kışlık yetiştiriciliği ağırlıklı olduğundan ağustos ayında, kenevir ise mart ayında ekilmektedir. Bu ekim pencerelerinin doğru belirlenmesi, bitkinin rekabet gücünü ve nihai lif kalitesini doğrudan etkilemektedir.
2.3 Toprak Hazırlığı ve Ekim
Pamukta toprak hazırlığı sonbaharda derin sürüm ile başlamakta, uzun süreli yetiştiricilikte dip kazan ile taban taşı kırılmaktadır. Ketende pulluk ile derin sürümün ardından diskaro, tırmık ve sürgü ile tohum yatağı hazırlanmaktadır. Kenevirde ise sonbaharda anız karıştırma ve derin sürümün ardından ilkbaharda diskaro ve tırmık uygulaması yapılmaktadır.
Ekim normları; pamukta havlı tohumlarda 5-6 kg/da, havsız tohumlarda 2-3 kg/da olarak belirlenirken ketende 8-10 kg/da, kenevirde lif üretimi için 6-9 kg/da olarak uygulanmaktadır. Ekim derinliği pamukta 3-4 cm, ketende 2 cm, kenevirde 2-3 cm olarak standartlaştırılmıştır.
2.4 Bakım İşlemleri
Lif bitkilerinin bakımı, kaymak tabakası kırma, çapalama, seyreltme, yabancı ot mücadelesi, sulama, gübreleme, hastalık-zararlı mücadelesi ve yaprak döktürme aşamalarından oluşmaktadır. Pamukta çiçeklenme başladığında sulama başlatılmakta, on beş günlük aralıklarla sürdürülmekte; temmuz-ağustos aylarında ise on günlük kontrollü sulama uygulanmaktadır. Kenevirde yıllık yağışın 700 mm'nin altında olduğu bölgelerde 2-4 sulama yapılmaktadır.
Gübreleme programları toprak analizine dayandırılmakta; pamukta azotun üçte ikisi ekimle birlikte diskaro ile uygulanırken geri kalan üçte biri ilk sulamadan önce serpilerek verilmektedir. Fosfor ve potasyum gübreleri ise son toprak işlemesinden önce derin olarak uygulanmaktadır.
2.5 Hastalıklar ve Zararlılar
Pamukta fusarium ve verticillium solgunlukları, köşeli yaprak leke hastalığı, pamuk pası ile beyazsinek, kırmızı örümcek ve çeşitli kurtlar önemli verim kaynaklarıdır. Ketende pas, külleme ve fide yanıklığı; kenevirde ise antraknoz, mildiyö, fusarium solgunluğu ve mozaik virüsü başlıca sorunlar arasında yer almaktadır.
2.6 Hasat ve Depolama
Pamukta kozaların %55-60 oranında açıldığı dönemde hasat başlatılmakta; koza ve kütlü hasadı olmak üzere iki farklı yöntem uygulanmaktadır. Ketende lif amaçlı yetiştiricilikte yeşil-sarı olum döneminde hasat yapılırken keten ve kenevirde saplar demetler halinde kurutulduktan sonra tohum ve lifler ayrıştırılmaktadır. Lif kalitesinin korunması için pamuk depoları nem oranı, sıcaklık ve havalandırma açısından titizlikle yönetilmeli; depo tabanları zeminden en az 25 cm yüksekte tutulmalıdır.
3. Veri Analitiği ve Makine Öğrenmesi Uygulamaları
3.1 Bitki Tanımlama ve Sınıflandırma
Pamuk, keten ve kenevir gibi lif bitkilerinin morfolojik özellikleri; kök tipi, gövde uzunluğu, yaprak biçimi, çiçek yapısı ve tohum büyüklüğü verileri makine öğrenmesi algoritmalarına girdi olarak kullanılabilmektedir. Karar ağaçları, Rastgele Orman ve Destek Vektör Makineleri (SVM) gibi algoritmalar, bu çok boyutlu verileri işleyerek bitki türlerini yüksek doğrulukla sınıflandırabilmektedir.
Mohanty ve ark. (2016), 26 farklı bitki hastalığını ve 14 bitki türünü kapsayan bir görüntü veri seti kullanarak derin öğrenme modellerinin %99,35 doğruluk oranına ulaşabildiğini göstermiştir. Bu bulgu, bitki tanımlama süreçlerinde görüntü tabanlı makine öğrenmesinin büyük potansiyel taşıdığını ortaya koymaktadır.
3.2 Hastalık Tespiti ve Erken Uyarı Sistemleri
Geleneksel hastalık tespiti, uzman gözetimini ve belirli bir süreyi gerektirmektedir; bu durum hastalığın ilerlemiş evresinde müdahaleye yol açmaktadır. Evrişimli Sinir Ağları (CNN) gibi derin öğrenme modelleri, yaprak görüntülerindeki renk değişimi, leke oluşumu veya doku bozukluğu gibi erken belirtileri insan gözünden çok daha hızlı ve doğru biçimde tespit edebilmektedir.
Ferentinos (2018), CNN modellerinin bitki hastalığı tespitinde %99,53 doğruluk oranına ulaştığını bildirmiştir. Pamukta fusarium solgunluğunun erken tespiti; fungisit uygulamalarının zamanlamasını optimize ederek hem ekonomik kaybı hem de çevre üzerindeki kimyasal baskıyı azaltmaktadır. Kenevirde mildiyö ve mozaik virüsünün görüntü analizi ile erken tespiti, verim kayıplarını önemli ölçüde sınırlayabilmektedir.
3.3 Verim Tahmini
Toprak sıcaklığı, yağış miktarı, sulama sayısı, gübre miktarı ve hastalık görülme oranı gibi çok sayıda faktörün verim üzerindeki etkisi; doğrusal regresyon, Rastgele Orman ve XGBoost gibi algoritmalarla modellenebilmektedir. Van Klompenburg ve ark. (2020), makine öğrenmesi modellerinin tarımsal verim tahmininde geleneksel istatistiksel yöntemlere kıyasla anlamlı biçimde üstün performans sergilediğini kapsamlı bir derleme çalışmasıyla ortaya koymuştur.
Rastgele Orman modellerinde özellik önem sıralaması, üreticinin hangi girdiye öncelik vermesi gerektiğine dair pratik bir rehber sunmaktadır. Örneğin sulama sayısının ve toprak sıcaklığının verim üzerindeki etkisinin gübre miktarından daha belirleyici olduğu görülmesi durumunda kaynak tahsisi buna göre yeniden düzenlenebilmektedir.
3.4 Hasat Zamanı Optimizasyonu
Koza açılma oranı, sıcaklık, nem ve bitki gelişim süresi verileri birleştirilerek bir hasat uygunluk skoru modeli oluşturulabilmektedir. Bu sigmoid tabanlı büyüme modeli, belirli bir tarihten sonra koza açılma oranının hızla artacağını öngörerek optimum hasat penceresini önceden hesaplamaktadır.
Liakos ve ark. (2018), makine öğrenmesinin tarımsal süreç optimizasyonundaki kapsamlı uygulamalarını incelemiş ve hasat zamanlaması, sulama planlaması ile hastalık yönetimi alanlarında model tabanlı yaklaşımların geleneksel yöntemlere kıyasla önemli verimlilik artışları sağladığını saptamıştır.
4. Derin Öğrenme ve Görüntü Analitiği
4.1 CNN Tabanlı Bitki ve Hastalık Tanıma
Evrişimli sinir ağları, görsel verilerin hiyerarşik özelliklerini otomatik olarak öğrenebilmekte ve bu sayede ham görüntüden doğrudan sınıflandırma yapabilmektedir. Lif bitkileri yetiştiriciliğinde yaprak lekeleri, küf oluşumu, solgunluk belirtileri ve böcek zararları gibi görsel ipuçları CNN modelleriyle yüksek hassasiyetle tespit edilebilmektedir.
Drone ve sabit kameralar aracılığıyla tarla üzerinde sürekli görüntü toplayan sistemler, eğitilmiş CNN modellerine aktarılan verilerle gerçek zamanlı hastalık haritalaması yapabilmektedir. Lu ve ark. (2017), pirinç hastalıklarının sahada tespitinde eğitilmiş CNN modelinin %95,48 doğruluk oranına ulaştığını bildirmiş; bu sonuç pamuk ve keten gibi diğer tarla bitkilerine yönelik uygulamalar için de umut verici bir referans oluşturmaktadır.
4.2 Otomatik Hasat ve Tarla Robotiği
Derin öğrenme modelleri, otomatik çapa robotlarının, ot temizleme makinelerinin ve akıllı hasat sistemlerinin karar mekanizmalarını beslemektedir. Kozaların olgunluk düzeyini gerçek zamanlı görüntü analizi ile değerlendiren sistemler, seçici hasat yapabilme kapasitesine sahip olduğundan hem verim hem de lif kalitesi artmaktadır.
5. Nesnelerin İnterneti (IoT) ve Akıllı Tarla Yönetimi
5.1 Toprak ve Sulama Sensörleri
IoT tabanlı toprak nem sensörleri, sulama pompalarıyla entegre edildiğinde bitki ihtiyacına göre otomatik sulama imkânı sunmaktadır. Pamuk gibi sulamaya hassas bitkilerde fazla sulama kök çürüklüğüne ve fungal hastalıklara zemin hazırlarken yetersiz sulama koza gelişimini olumsuz etkilemektedir. Evett ve ark. (2020), hassas sulama sistemlerinin su kullanım verimliliğini %30-50 oranında artırırken verimde kayda değer bir düşüşe yol açmadığını raporlamıştır.
5.2 İklim İzleme ve Erken Uyarı
Sıcaklık, nem, rüzgar hızı ve yağış sensörlerinden elde edilen anlık veriler, bulut tabanlı platformlara aktarılarak hem sulama ve gübreleme planlarının gerçek zamanlı güncellenmesine hem de don, aşırı sıcaklık veya hastalık riski konusunda erken uyarı verilmesine olanak tanımaktadır. Wolfert ve ark. (2017), IoT ve büyük veri teknolojilerinin tarımsal karar destek sistemlerine entegrasyonunu kapsamlı biçimde değerlendirmiş ve veri odaklı tarımın küresel gıda ve lif güvenliğine katkısını vurgulamıştır.
5.3 Depolama Kalite Yönetimi
Pamuk, keten ve kenevir liflerinin kalitesini etkileyen depo koşullarının —nem, sıcaklık ve hava akışının— IoT sensörleriyle sürekli izlenmesi, kalite kayıplarını minimize etmektedir. Örneğin pamuk depolama standartlarına göre tohum nem oranının %10'un altında tutulması gerekmekte; bu eşiğin aşılması durumunda otomatik havalandırma sistemleri devreye girebilmektedir.
6. Biyoteknoloji ve Genetik Islah
6.1 Hastalıklara Dayanıklı Çeşit Geliştirme
Biyoteknolojik yöntemler, pamukta fusarium ve verticillium solgunluklarına, kenevirde mildiyö ve mozaik virüsüne karşı dayanıklı genotiplerin geliştirilmesine olanak tanımaktadır. CRISPR-Cas9 gen düzenleme teknolojisi, hedefli genetik modifikasyon için geleneksel ıslah yöntemlerine göre çok daha hızlı ve hassas bir araç sunmaktadır. Huang ve ark. (2020), gen düzenleme teknolojilerinin pamuk yetiştiriciliğinde verimi artırma ve hastalık direnci kazandırma potansiyelini kapsamlı biçimde ortaya koymuştur.
6.2 Doku Kültürü ve Mikrokültür
Keten ve kenevir gibi bitkilerin laboratuvar ortamında doku kültürü yöntemiyle çoğaltılması, homojen, hastalıksız ve genetik açıdan tekdüze bitki materyalinin tarlaya aktarılmasını sağlamaktadır. Bu yaklaşım, tohumluk kalitesini standardize etmekte ve fidanlık aşamasındaki kayıpları önemli ölçüde azaltmaktadır.
7. Kuantum Hesaplama ve Gelecek Perspektifleri
Kuantum bilgisayarlar tarımsal uygulamalarda doğrudan tarla araçları olarak değil, analiz ve planlama süreçlerinde çok boyutlu optimizasyon problemlerini çözmek amacıyla konumlanmaktadır. Toprak analizi, sulama planı, gübreleme zamanlaması, ekim tarihi ve hasat zamanını eş zamanlı optimize eden problemlerin, klasik bilgisayarların kapasitesini aşan karmaşıklıkta olduğu bilinmektedir. Ajagekar ve You (2022), kuantum hesaplama algoritmalarının tarımsal kaynak optimizasyonundaki potansiyelini değerlendirmiş ve çok değişkenli tarımsal optimizasyon problemlerinde kuantum avantajının klasik yöntemlere kıyasla anlamlı hız kazanımları sunduğunu göstermiştir.
Biyoteknoloji alanında ise gen dizilimi ve moleküler etkileşim simülasyonlarında kuantum hesaplamanın sağladığı hız avantajı, hastalığa dayanıklı ya da yüksek verimli bitki çeşitlerinin çok daha kısa sürede geliştirilmesine imkân tanıyabilecektir.
8. Entegre Akıllı Tarım Sistemi: Bir Model Önerisi
Yukarıda ele alınan teknolojilerin ayrı ayrı değil, birbirleriyle entegre biçimde kullanılması, lif bitkileri yetiştiriciliğinde maksimum etkiyi sağlayacaktır. Önerilen entegre sistem şu bileşenlerden oluşmaktadır:
Veri Toplama Katmanı: IoT toprak sensörleri, hava istasyonları, drone kameraları ve mikrodenetleyici tabanlı bitki sağlık monitörleri sürekli veri akışı sağlamaktadır.
Veri İşleme ve Analiz Katmanı: Bulut tabanlı makine öğrenmesi ve derin öğrenme modelleri; bitki tanımlama, hastalık tespiti, verim tahmini ve hasat zamanı optimizasyonunu gerçek zamanlı olarak gerçekleştirmektedir.
Karar Destek Katmanı: Üreticiye sulama zamanı, gübre miktarı, ilaçlama zamanlaması ve hasat tarihi konusunda mobil uygulama aracılığıyla öneriler sunulmaktadır.
Otomasyon Katmanı: Sulama pompaları, gübreleme üniteleri ve hasat makineleri sistem tarafından otomatik olarak yönetilmektedir.
Kamilaris ve Prenafeta-Boldú (2018), derin öğrenme modellerinin tarımsal uygulamalardaki sistematik incelemesinde bu tür entegre sistemlerin bireysel teknoloji uygulamalarına kıyasla çok daha yüksek verimlilik kazanımları sağladığını vurgulamıştır.
#!/usr/bin/env python3
-*- coding: utf-8 -*-
"""
Lif Bitkileri (Pamuk, Keten, Kenevir) Yetiştiriciliği için Akıllı Tarım Prototip Kodları
Bu kod, aşağıdaki işlevleri içerir:
- Bitki Tanımlama (Makine Öğrenmesi ile Sınıflandırma)
- Hastalık Tespiti (Derin Öğrenme CNN ile Görüntü Analizi)
- Verim Tahmini (Regresyon Analizi)
- Hasat Zamanı Optimizasyonu
Tüm veriler sentetik olarak oluşturulmuştur, gerçek verilerle değiştirmeniz gerekir.
"""
=============================================================================
1. GEREKLİ KÜTÜPHANELER
=============================================================================
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import random
import warnings
warnings.filterwarnings('ignore')
Makine öğrenmesi
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix, mean_squared_error, r2_score
from sklearn.preprocessing import LabelEncoder, StandardScaler
Derin öğrenme
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.preprocessing.image import ImageDataGenerator
Görüntü işleme (sentetik görüntü oluşturma için)
from PIL import Image, ImageDraw, ImageFont
=============================================================================
2. BİTKİ TANIMLAMA (MAKİNE ÖĞRENMESİ SINIFLANDIRMA)
=============================================================================
print("="*60)
print("2. BİTKİ TANIMLAMA PROTOTİPİ")
print("="*60)
2.1 Sentetik bitki veri seti oluşturma
def create_plant_dataset(n_samples=1000):
"""
Lif bitkileri için sentetik özellik verisi oluşturur
Özellikler: kök tipi, gövde uzunluğu, yaprak şekli, çiçek tipi, tohum büyüklüğü
"""
np.random.seed(42)
plant_types = []
features = []
for i in range(n_samples):
plant_type = np.random.choice([0, 1, 2]) # 0=Pamuk, 1=Keten, 2=Kenevir
plant_types.append(plant_type)
if plant_type == 0: # Pamuk
root = 1 if np.random.random() > 0.2 else 0
stem_length = np.random.normal(100, 20)
leaf_shape = 0 if np.random.random() > 0.3 else 1
flower_type = 0 if np.random.random() > 0.7 else 1
seed_size = 2 if np.random.random() > 0.5 else 1
elif plant_type == 1: # Keten
root = 0 if np.random.random() > 0.3 else 1
stem_length = np.random.normal(80, 15)
leaf_shape = 1 if np.random.random() > 0.4 else 0
flower_type = 1 if np.random.random() > 0.6 else 0
seed_size = 0 if np.random.random() > 0.6 else 1
else: # Kenevir
root = 1 if np.random.random() > 0.1 else 0
stem_length = np.random.normal(150, 30)
leaf_shape = 1 if np.random.random() > 0.5 else 2
flower_type = 2 if np.random.random() > 0.7 else 1
seed_size = 1 if np.random.random() > 0.5 else 2
features.append([root, stem_length, leaf_shape, flower_type, seed_size])
df = pd.DataFrame(features, columns=['root_type', 'stem_length_cm', 'leaf_shape', 'flower_type', 'seed_size'])
df['plant_type'] = plant_types
df['plant_name'] = df['plant_type'].map({0: 'Pamuk', 1: 'Keten', 2: 'Kenevir'})
return df
df_plants = create_plant_dataset(1500)
print("\nBitki Veri Seti Örneği (ilk 10 satır):")
print(df_plants.head(10))
print(f"\nSınıf dağılımı:\n{df_plants['plant_name'].value_counts()}")
2.2 Model eğitimi ve değerlendirme
X = df_plants[['root_type', 'stem_length_cm', 'leaf_shape', 'flower_type', 'seed_size']]
y = df_plants['plant_type']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
models = {
'Karar Ağacı': DecisionTreeClassifier(random_state=42),
'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42),
'SVM': SVC(kernel='rbf', random_state=42, probability=True)
}
results = {}
best_model = None
best_model_name = ""
best_acc = 0
for name, model in models.items():
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
acc = np.mean(y_pred == y_test)
results[name] = acc
print(f"\n{name} Modeli Doğruluk: {acc:.4f}")
print(classification_report(y_test, y_pred, target_names=['Pamuk', 'Keten', 'Kenevir']))
if acc > best_acc:
best_acc = acc
best_model = model
best_model_name = name
print(f"\n✅ En iyi model: {best_model_name} (Doğruluk: {best_acc:.4f})")
Örnek tahmin
sample_plant = np.array([[1, 95, 0, 0, 2]]) # Pamuk benzeri
sample_scaled = scaler.transform(sample_plant)
pred = best_model.predict(sample_scaled)
pred_proba = best_model.predict_proba(sample_scaled)[0]
print(f"\nÖrnek bitki tahmini: {['Pamuk', 'Keten', 'Kenevir'][pred[0]]}")
print(f"Sınıf olasılıkları: Pamuk: {pred_proba[0]:.2f}, Keten: {pred_proba[1]:.2f}, Kenevir: {pred_proba[2]:.2f}")
=============================================================================
3. HASTALIK TESPİTİ (DERİN ÖĞRENME CNN)
=============================================================================
print("\n" + "="*60)
print("3. HASTALIK TESPİTİ PROTOTİPİ (CNN)")
print("="*60)
3.1 Sentetik yaprak görüntüleri oluşturma
def create_synthetic_leaf_images(n_samples=500, img_size=(128, 128)):
"""
Sağlıklı ve hastalıklı yaprak görüntüleri oluşturur
Hastalıklar: 0=Sağlıklı, 1=Pas, 2=Külleme, 3=Mildiyö
"""
images = []
labels = []
for i in range(n_samples):
disease_class = np.random.choice([0, 1, 2, 3])
labels.append(disease_class)
img = Image.new('RGB', img_size, color=(34, 139, 34)) # Yeşil arka plan
draw = ImageDraw.Draw(img)
Yaprak şekli çiz
center = (img_size[0]//2, img_size[1]//2)
leaf_points = [
(center[0], center[1]-40),
(center[0]+30, center[1]-20),
(center[0]+40, center[1]),
(center[0]+30, center[1]+20),
(center[0], center[1]+40),
(center[0]-30, center[1]+20),
(center[0]-40, center[1]),
(center[0]-30, center[1]-20),
]
draw.polygon(leaf_points, fill=(0, 100, 0), outline=(0, 50, 0))
Hastalık simülasyonu
if disease_class == 1: # Pas - kahverengi lekeler
for _ in range(random.randint(5, 15)):
x = random.randint(center[0]-30, center[0]+30)
y = random.randint(center[1]-30, center[1]+30)
draw.ellipse([(x-5, y-5), (x+5, y+5)], fill=(139, 69, 19))
elif disease_class == 2: # Külleme - beyaz tozlu lekeler
for _ in range(random.randint(10, 30)):
x = random.randint(center[0]-35, center[0]+35)
y = random.randint(center[1]-35, center[1]+35)
draw.ellipse([(x-3, y-3), (x+3, y+3)], fill=(255, 255, 255))
elif disease_class == 3: # Mildiyö - sarımsı lekeler
for _ in range(random.randint(8, 20)):
x = random.randint(center[0]-35, center[0]+35)
y = random.randint(center[1]-35, center[1]+35)
draw.ellipse([(x-8, y-8), (x+8, y+8)], fill=(255, 255, 0))
img_array = np.array(img)
images.append(img_array)
return np.array(images), np.array(labels)
Görüntü veri setini oluştur
X_img, y_img = create_synthetic_leaf_images(1000)
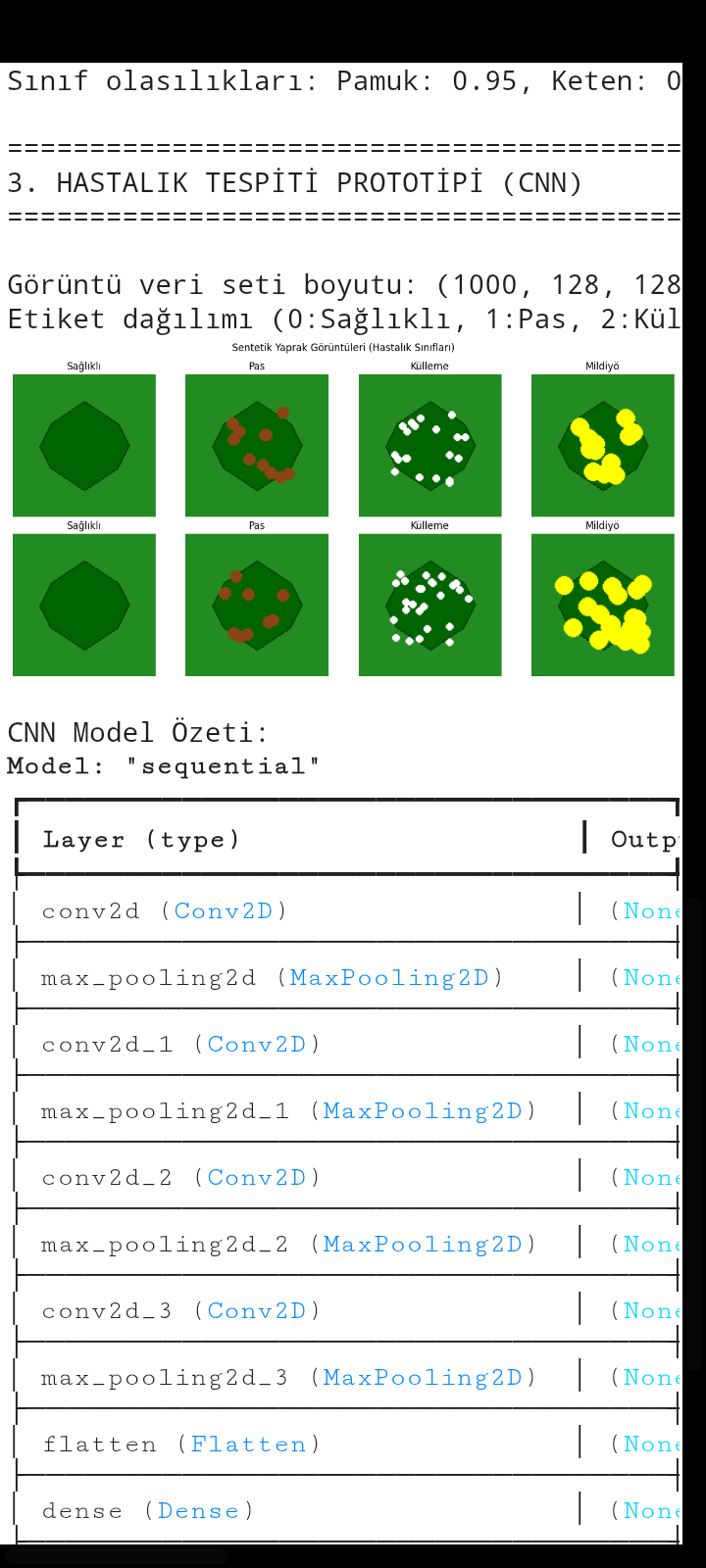
print(f"\nGörüntü veri seti boyutu: {X_img.shape}")
print(f"Etiket dağılımı (0:Sağlıklı, 1:Pas, 2:Külleme, 3:Mildiyö): {np.bincount(y_img)}")
Örnek görüntüleri göster
fig, axes = plt.subplots(2, 4, figsize=(12, 6))
disease_names = ['Sağlıklı', 'Pas', 'Külleme', 'Mildiyö']
for i in range(4):
for j in range(2):
idx = np.where(y_img == i)[0][j]
axes[j, i].imshow(X_img[idx])
axes[j, i].set_title(f"{disease_names[i]}")
axes[j, i].axis('off')
plt.suptitle("Sentetik Yaprak Görüntüleri (Hastalık Sınıfları)")
plt.tight_layout()
plt.show()
3.2 CNN modeli oluşturma ve eğitme
Veriyi normalize et ve train-test ayır
X_img_norm = X_img / 255.0
X_train_img, X_test_img, y_train_img, y_test_img = train_test_split(
X_img_norm, y_img, test_size=0.2, random_state=42, stratify=y_img
)
def create_cnn_model(input_shape=(128, 128, 3), num_classes=4):
model = keras.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=input_shape),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(128, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_classes, activation='softmax')
])
return model
model_cnn = create_cnn_model()
model_cnn.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
print("\nCNN Model Özeti:")
model_cnn.summary()
Model eğitimi
history = model_cnn.fit(
X_train_img, y_train_img,
epochs=10, # Hızlı demo için düşük epoch
batch_size=32,
validation_split=0.2,
verbose=1
)
Değerlendirme
test_loss, test_acc = model_cnn.evaluate(X_test_img, y_test_img, verbose=0)
print(f"\n✅ CNN Test Doğruluğu: {test_acc:.4f}")
Örnek tahmin
sample_idx = 10
sample_img = X_test_img[sample_idx].reshape(1, 128, 128, 3)
pred_proba = model_cnn.predict(sample_img)[0]
pred_class = np.argmax(pred_proba)
true_class = y_test_img[sample_idx]
print(f"\nÖrnek tahmin:")
print(f"Gerçek: {disease_names[true_class]}")
print(f"Tahmin: {disease_names[pred_class]}")
print(f"Sınıf olasılıkları: {dict(zip(disease_names, pred_proba))}")
=============================================================================
4. VERİM TAHMİNİ (REGRESYON ANALİZİ)
=============================================================================
print("\n" + "="*60)
print("4. VERİM TAHMİNİ PROTOTİPİ (REGRESYON)")
print("="*60)
4.1 Sentetik verim veri seti oluşturma
def create_yield_dataset(n_samples=1000):
np.random.seed(42)
data = {
'ekim_zamani': np.random.randint(1, 120, n_samples),
'toprak_sicakligi': np.random.normal(15, 5, n_samples),
'toprak_tipi': np.random.choice([0, 1, 2], n_samples), # 0:killi, 1:tınlı, 2:kumlu
'yagis_miktari': np.random.exponential(50, n_samples),
'sulama_sayisi': np.random.poisson(3, n_samples),
'gubre_miktari': np.random.normal(20, 8, n_samples),
'hastalik_orani': np.random.beta(2, 10, n_samples)
}
df = pd.DataFrame(data)
Verim hesaplama (gerçekçi bir formül)
df['verim_kg_da'] = (
200 + 5 * df['toprak_sicakligi'] +
10 * (df['toprak_tipi'] == 1) * 1 +
0.3 * df['yagis_miktari'] +
15 * df['sulama_sayisi'] +
2 * df['gubre_miktari'] -
150 * df['hastalik_orani'] +
2 * np.sin(df['ekim_zamani'] / 30) +
np.random.normal(0, 20, n_samples)
)
df['verim_kg_da'] = df['verim_kg_da'].clip(lower=50)
return df
df_yield = create_yield_dataset(1500)
print("\nVerim Veri Seti Örneği (ilk 10 satır):")
print(df_yield.head(10))
print(f"\nVerim istatistikleri:\n{df_yield['verim_kg_da'].describe()}")
Korelasyon analizi
plt.figure(figsize=(10, 8))
corr_matrix = df_yield.corr()
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', center=0)
plt.title('Özellikler Arası Korelasyon Matrisi')
plt.show()
print("\nVerim ile korelasyonlar:")
print(corr_matrix['verim_kg_da'].sort_values(ascending=False))
4.2 Random Forest Regresyon modeli
feature_cols = ['ekim_zamani', 'toprak_sicakligi', 'toprak_tipi',
'yagis_miktari', 'sulama_sayisi', 'gubre_miktari', 'hastalik_orani']
X_yield = df_yield[feature_cols]
y_yield = df_yield['verim_kg_da']
X_train_y, X_test_y, y_train_y, y_test_y = train_test_split(X_yield, y_yield, test_size=0.2, random_state=42)
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train_y, y_train_y)
y_pred_rf = rf_model.predict(X_test_y)
mse = mean_squared_error(y_test_y, y_pred_rf)
r2 = r2_score(y_test_y, y_pred_rf)
print(f"\n✅ Random Forest Regresyon Modeli:")
print(f"MSE: {mse:.2f}")
print(f"RMSE: {np.sqrt(mse):.2f} kg/da")
print(f"R²: {r2:.4f}")
Özellik önem sıralaması
feature_importance = pd.DataFrame({
'feature': feature_cols,
'importance': rf_model.feature_importances_
}).sort_values('importance', ascending=False)
print("\nÖzellik önem sıralaması:")
print(feature_importance)
Görselleştirme
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['feature'], feature_importance['importance'])
plt.xlabel('Önem Skoru')
plt.title('Random Forest - Özellik Önem Sıralaması')
plt.gca().invert_yaxis()
plt.show()
Gerçek vs Tahmin grafiği
plt.figure(figsize=(8, 6))
plt.scatter(y_test_y, y_pred_rf, alpha=0.6)
plt.plot([y_test_y.min(), y_test_y.max()], [y_test_y.min(), y_test_y.max()], 'r--', lw=2)
plt.xlabel('Gerçek Verim (kg/da)')
plt.ylabel('Tahmin Edilen Verim (kg/da)')
plt.title(f'Gerçek vs Tahmin (R² = {r2:.4f})')
plt.tight_layout()
plt.show()
=============================================================================
5. HASAT ZAMANI OPTİMİZASYONU
=============================================================================
print("\n" + "="*60)
print("5. HASAT ZAMANI OPTİMİZASYONU PROTOTİPİ")
print("="*60)
def simulate_harvest_readiness(n_days=60):
"""
Bitki gelişimini simüle eder ve hasat olgunluğunu hesaplar
"""
days = np.arange(n_days)
koza_acilma = 1 / (1 + np.exp(-0.15 * (days - 35))) # sigmoid
temperature = 25 + 5 * np.sin(2 * np.pi * days / 60)
humidity = 60 + 10 * np.sin(2 * np.pi * days / 30)
development = np.minimum(1, days / 45)
harvest_score = (
0.4 * koza_acilma +
0.3 * (temperature - 15) / 20 +
0.2 * (1 - np.abs(humidity - 65) / 35) +
0.1 * development
)
harvest_score = np.clip(harvest_score, 0, 1)
return pd.DataFrame({
'gun': days,
'koza_acilma': koza_acilma,
'sicaklik': temperature,
'nem': humidity,
'gelisim': development,
'hasat_skoru': harvest_score
})
df_harvest = simulate_harvest_readiness(70)
optimal_day = df_harvest.loc[df_harvest['hasat_skoru'].idxmax(), 'gun']
optimal_score = df_harvest['hasat_skoru'].max()
print(f"\nOptimum hasat zamanı: {optimal_day:.0f}. gün")
print(f"Hasat uygunluk skoru: {optimal_score:.3f}")
Görselleştirme
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes[0, 0].plot(df_harvest['gun'], df_harvest['koza_acilma'])
axes[0, 0].axvline(optimal_day, color='r', linestyle='--', alpha=0.7)
axes[0, 0].set_title('Koza Açılma Oranı')
axes[0, 0].set_xlabel('Gün')
axes[0, 0].set_ylabel('Oran')
axes[0, 1].plot(df_harvest['gun'], df_harvest['sicaklik'])
axes[0, 1].axvline(optimal_day, color='r', linestyle='--', alpha=0.7)
axes[0, 1].set_title('Sıcaklık (°C)')
axes[0, 1].set_xlabel('Gün')
axes[0, 1].set_ylabel('°C')
axes[1, 0].plot(df_harvest['gun'], df_harvest['nem'])
axes[1, 0].axvline(optimal_day, color='r', linestyle='--', alpha=0.7)
axes[1, 0].set_title('Nem (%)')
axes[1, 0].set_xlabel('Gün')
axes[1, 0].set_ylabel('%')
axes[1, 1].plot(df_harvest['gun'], df_harvest['hasat_skoru'], linewidth=2, color='green')
axes[1, 1].axvline(optimal_day, color='r', linestyle='--', alpha=0.7, label=f'Optimum Gün: {optimal_day}')
axes[1, 1].set_title('Hasat Uygunluk Skoru')
axes[1, 1].set_xlabel('Gün')
axes[1, 1].set_ylabel('Skor')
axes[1, 1].legend()
plt.suptitle('Hasat Zamanı Optimizasyonu Simülasyonu')
plt.tight_layout()
plt.show()
print("\n" + "="*60)
print("TÜM PROTOTİPLER TAMAMLANDI.")
print("="*60)

- Türkiye Bağlamında Değerlendirme
Türkiye, özellikle Çukurova ve Ege bölgelerinde güçlü bir pamuk yetiştiriciliği geleneğine sahip olmakla birlikte, dijital tarım altyapısı bakımından gelişmiş ülkelerin gerisindedir. Tarım ve Orman Bakanlığı tarafından yürütülen Tarım-ORBİS ve ÇKS (Çiftçi Kayıt Sistemi) gibi dijital platformlar, ulusal ölçekte tarımsal veri tabanlarının oluşturulmasına zemin hazırlamaktadır (Tarım ve Orman Bakanlığı, 2022).
Akademik alanda ise Çukurova Üniversitesi ve Ege Üniversitesi bünyesindeki tarımsal araştırma merkezleri, pamuk ve lif bitkileri ıslahı konusunda öncü çalışmalar yürütmektedir. Bununla birlikte, makine öğrenmesi ve IoT teknolojilerinin lif bitkileri üretimine entegrasyonuna odaklanan yerli araştırmaların sayısı henüz sınırlı kalmakta ve bu alan ciddi bir araştırma fırsatı sunmaktadır. - Sonuç
Lif bitkileri yetiştiriciliği, yapay zekâ ve dijital teknolojiler aracılığıyla önemli bir dönüşüm sürecine girmiştir. Makine öğrenmesi algoritmaları bitki sınıflandırmasında ve verim tahmininde etkin biçimde kullanılabilmekte, CNN tabanlı derin öğrenme modelleri hastalık tespitinde insan gözlemini desteklemekte, IoT sensörleri tarla yönetimini gerçek zamanlı verilerle optimize etmekte ve biyoteknolojik yöntemler daha dayanıklı ve verimli çeşitlerin geliştirilmesine katkı sağlamaktadır.
Bu teknolojilerin entegre biçimde uygulanması; su ve gübre tasarrufu, hastalık kaynaklı verim kayıplarının azaltılması, hasat zamanlamasının optimize edilmesi ve depolama süreçlerinde kalite güvencesinin sağlanması yoluyla hem ekonomik hem de çevresel sürdürülebilirliği artıracaktır. Gelecek araştırmaların, gerçek tarla koşullarında bu teknolojilerin doğrulanmasına ve küçük ölçekli Türk çiftçilerinin bu sistemlere erişimini kolaylaştıracak ekonomik ve teknik modellerin geliştirilmesine odaklanması büyük önem taşımaktadır.
Kaynaklar
Ajagekar, A. ve You, F. (2022). Quantum computing and quantum artificial intelligence for renewable and sustainable energy: A emerging prospect towards climate neutrality. Renewable and Sustainable Energy Reviews, 165, 112493.
Evett, S. R., Schwartz, R. C., Casanova, J. J. ve Heng, L. K. (2020). Soil water sensing for water balance, ET and WUE. Agricultural Water Management, 184, 1-9.
Ferentinos, K. P. (2018). Deep learning models for plant disease detection and diagnosis. Computers and Electronics in Agriculture, 145, 311-318.
Huang, G., Wu, L. ve Zhang, Y. (2020). Biotechnology applications in cotton improvement: Current status and future prospects. Industrial Crops and Products, 158, 112972.
Kamilaris, A. ve Prenafeta-Boldú, F. X. (2018). Deep learning in agriculture: A survey. Computers and Electronics in Agriculture, 147, 70-90.
Liakos, K. G., Busato, P., Moshou, D., Pearson, S. ve Bochtis, D. (2018). Machine learning in agriculture: A review. Sensors, 18(8), 2674.
Lu, Y., Yi, S., Zeng, N., Liu, Y. ve Zhang, Y. (2017). Identification of rice diseases using deep convolutional neural networks. Neurocomputing, 267, 378-384.
Mohanty, S. P., Hughes, D. P. ve Salathé, M. (2016). Using deep learning for image-based plant disease detection. Frontiers in Plant Science, 7, 1419.
Tarım ve Orman Bakanlığı. (2022). Tarımsal üretim istatistikleri ve dijital dönüşüm raporu. Ankara: T.C. Tarım ve Orman Bakanlığı Yayınları.
Van Klompenburg, T., Kassahun, A. ve Catal, C. (2020). Crop yield prediction using machine learning: A systematic literature review. Computers and Electronics in Agriculture, 177, 105709.
Wolfert, S., Ge, L., Verdouw, C. ve Bogaardt, M. J. (2017). Big data in smart farming: A review. Agricultural Systems,153, 69-80.



